AI Support Guides
Last Updated:

Akash Tanwar

IN this article
Enterprise AI support teams spend twenty hours a week tuning their bot. That is not an AI problem. It is an architecture problem. This post walks through the four commitments that make self-maintenance real, the tradeoffs we made, and what it looks like at three million monthly resolutions.
Every AI support team I talk to has the same week-six conversation. The rollout went well. Resolution numbers look good. Then the product team ships a policy change, or a country goes live, or a pricing tier gets renamed, and the agent starts getting things subtly wrong. So someone opens a ticket to "tune the bot."
That ticket never closes. It becomes a job.
Our wedge at Fini is four words: Live in 30 days. Never tune it again. Most readers assume the second sentence is positioning. It is not. It is an engineering commitment, and the only way to make it is to stop treating the knowledge base as an input and start treating it as a live system.
This post is what that means in production.
The tuning cycle is a design choice, not a law
Industry benchmarks from the last two years converge on an uncomfortable number: support teams running AI agents spend 18 to 22 hours per week maintaining the knowledge base that powers those agents. Writing articles. Reconciling duplicates. Updating policy pages. Flagging the old ones. Re-indexing. Reviewing the re-indexed version. Repeat every Monday.
That time is the cost of building an AI agent on top of a document-first architecture. Documents drift. Policies change faster than docs. Human agents find the answers in tickets, but tickets are not searchable by the bot, so the knowledge stays buried and the same question cycles back to the agent next week.
The common fix is to hire a "knowledge ops" lead. The better fix is to build an agent that writes the doc itself the first time a human resolves the question.
Fini's Knowledge Atlas is that mechanism. It is also why we can stand behind the second sentence of our wedge.
The real cost of twenty hours a week
It is worth converting the 20-hour tuning number into something concrete, because it is the single largest hidden cost of an AI support deployment. A knowledge operations lead at a North American fintech costs roughly $120,000 loaded. One lead is not enough past 200,000 tickets a month, so most teams scale to two. That is $240,000 a year before any AI license spend.
Add the second-order costs. Product managers sit in the weekly tuning sync because the questions the bot gets wrong often trace back to product decisions nobody documented. Compliance reviews every article that touches a regulated topic, which for fintech and healthcare is most of them. The ticket-to-article lead time is typically 10 to 14 days, which means for two weeks after any product change, some customers get the wrong answer and compliance absorbs the risk.
The fully loaded cost of the tuning cycle at a mid-sized fintech is closer to $500,000 a year than $250,000. This is the line item the AI support vendor does not put on the invoice. We put it on the invoice by refusing to need it.
Four commitments that make self-maintenance real
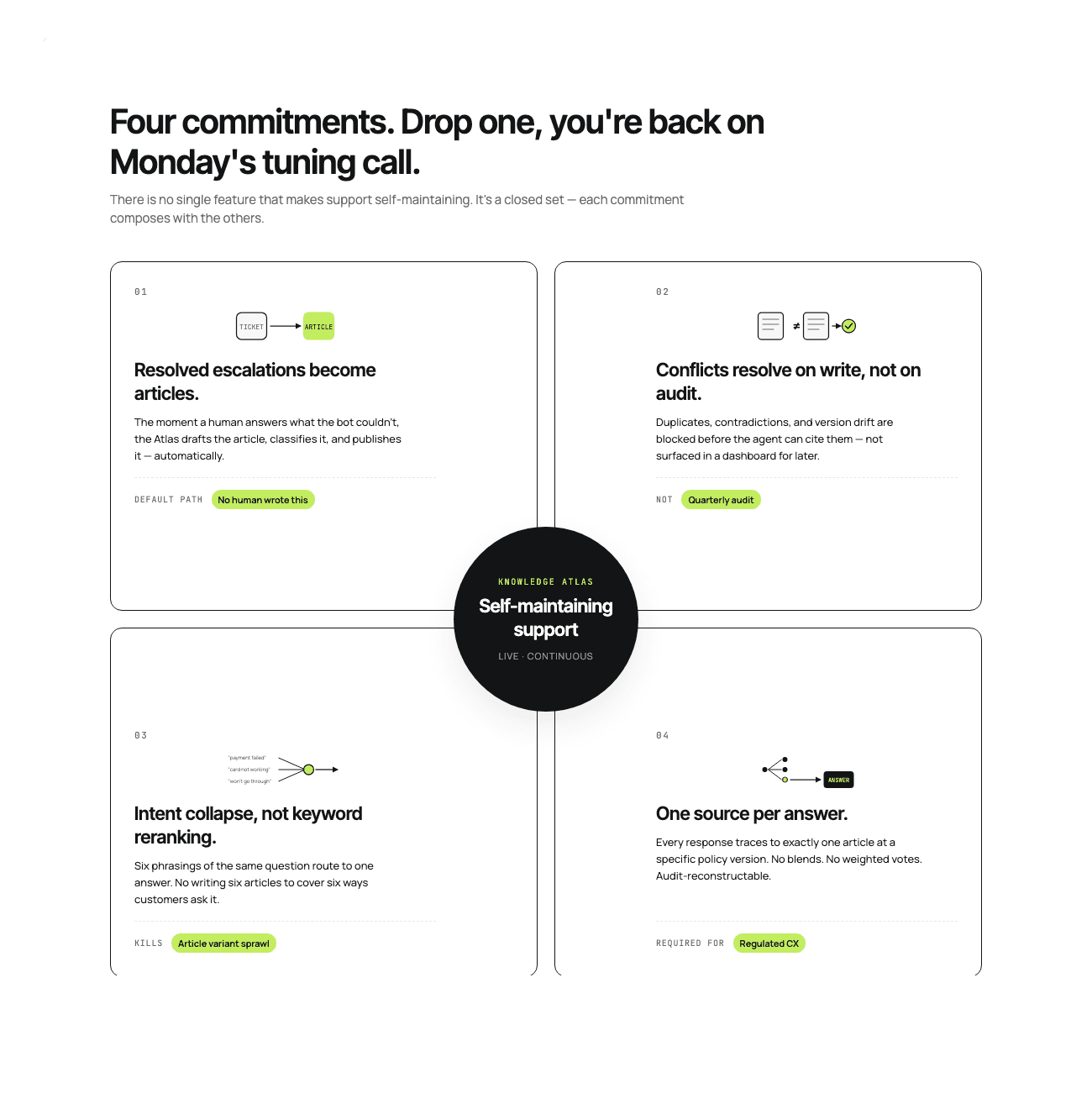
There is no single feature that makes support self-maintaining. There is a set of four commitments, and you have to make all of them. Drop one and you are back in the Monday tuning meeting.
1. Resolved escalations become articles, automatically
When a human agent resolves a ticket that the AI could not answer, the resolution is information the next agent needs. Most stacks lose it. The human types the answer in the ticket, the ticket closes, the knowledge base never learns.
Knowledge Atlas pulls that moment into a writable loop. It extracts the solution from the conversation, formats a help article around it, classifies it into the correct branch of the tree (Banking → Transfers → International, for example), and makes it searchable instantly. The next time a customer asks about international wire limits, the agent has a source. No human wrote it. No "knowledge ops" meeting scheduled it.
This is the only architecturally honest way to handle the long tail. The alternative is building a documentation team. Documentation teams do not scale with ticket volume. Resolved tickets do.
2. Conflict detection runs continuously, not on a quarterly audit
Knowledge bases contradict themselves. Two articles disagree on refund windows. An old policy lingers after a product change. A regional variant drifts out of sync with the US parent. Most teams discover the conflict when a customer gets the wrong answer.
Continuous conflict detection means the system surfaces duplicates, contradictions, and version mismatches on write, not on a schedule. When the auto-generated article from Section 1 contradicts an existing one, the system flags it against the current production policy and routes to a human for reconciliation before the agent can cite it.
The common failure here is shipping a dashboard and calling it done. A dashboard nobody opens does not prevent bad answers. The system has to block citation on conflict, then resolve, then unblock. That is a pipeline, not a report.
This is where architecture mistakes compound. A knowledge base of 2,000 articles can carry several hundred latent conflicts at any given time, most of them invisible until a specific customer query surfaces them. Without continuous detection, the retriever picks whichever article ranks highest on that query. That is how a regulated business tells one customer the refund window is 30 days and the next 45, on the same Wednesday.
3. Intent-collapsed retrieval, not keyword reranking
"Why won't my payment go through," "transaction failed at checkout," and "card not working" are the same question. Classical vector search treats them as three different queries because the wording is different, and retrieval quality drops to whichever version happened to match the article phrasing.
Intent collapse is the discipline of mapping every surface phrasing to the same underlying resolution. It is what lets one well-written article handle six real-world wordings at production quality. Without it, knowledge ops fills the gap by writing six variants of the same article, which is how you get to twenty hours a week.
This commitment has a cost we accept: the agent has to reason about intent before it retrieves, not after, which adds processing time per query. In exchange, we eliminate the single biggest driver of the tuning cycle, which is writing six variants of the same article to cover six real-world phrasings and then maintaining all six in parallel as policies change. RAG with a reranker does not do this. It retrieves by similarity and hopes the reranker filters the noise.
4. One authoritative source per answer
Every response the agent produces traces to exactly one article in the knowledge tree, not a blend across three retrievals or a weighted vote across the top five.
This sounds restrictive. It is actually the only way to pass a compliance review. In regulated CX, when a customer disputes an answer, the business has to reconstruct what the agent said and why. If the answer was blended across four articles, none of which match the response text, the audit fails. The regulator does not care that your retriever scored well.
One source per answer also cleans up the self-maintenance loop. When an article is wrong, you know which one. When a policy changes, you know what to update. When the Atlas flags a conflict, you know which source wins. The tree-structured knowledge graph is not a nice-to-have. It is what makes the other three commitments compose.
What we chose not to do
Every engineering system is defined as much by what it refuses as what it ships. Three decisions worth naming.
We do not rely on LLM-graded self-scoring. The industry has a bad habit of measuring AI support accuracy by asking another LLM to grade the transcript. That number is compatible with almost any reality. We measure on outcome: did the ticket close at the right state with no downstream escalation in 14 days? That is the only accuracy number we will publish and the only one we will commit against.
We do not alert on knowledge gaps and stop there. Teams have been shipping "your bot doesn't know X" dashboards for five years. A dashboard is not a fix. The Atlas writes the candidate article, proposes a tree location, and routes to the operator for one-click acceptance. The default path is not a human writing from scratch.
We do not let the KB mutate without reconciliation. New articles from resolved escalations are candidates, not publishes, until the conflict detector clears them against the current tree. This costs us some latency on the write path. It buys us the ability to say "one source per answer" without an asterisk.
What Day 1, Day 14, and Day 30 actually look like
The wedge promises a 30-day path to autonomy. That path has three discrete stages and each one does a specific job.
Day 1. The Knowledge Agent goes live on your existing helpdesk and KB. Five-second first response. FAQ-level resolution on everything the docs cover today. No code on your side. This stage validates the retrieval and response layer against your actual ticket shape.
Day 14. Agentic workflows turn on. The agent connects to billing, CRM, claims, or EHR depending on the vertical and starts taking actions: refunds, account updates, benefit lookups, data pulls. This is where resolution rate jumps from "answered" to "closed the ticket end to end." It is also where the Atlas starts auto-generating articles from the resolved escalations the human team handles in parallel.
Day 30. Self-learning is fully on. Voice, chat, and email run through one reasoning layer. Knowledge gaps get auto-detected and auto-drafted. The team stops writing articles. The Atlas does it from that week's resolution traffic. 95% of volume at 99% accuracy, and the number does not require a tuning cycle to hold.
The architecture choice that makes this timeline real is the same one that makes self-maintenance work: the KB is a live system, not an input.
The proof
Our anchor customer is Atlas, Crystal Stevens, Head of CX. They ran a three-stage rollout on their fintech support operation and moved from 15% automation to 70-80% on the key journeys, with answers in under 60 seconds. The second stat that matters more is the one you cannot see from the outside: their knowledge ops headcount is flat. They did not hire to maintain the system.
Aggregate across our fintech and healthcare cohort, Fini handles 3M+ monthly resolutions in production. That number is not held up by a maintenance team. It is held up by the four commitments above running continuously.
The knowledge tree has grown by tens of thousands of articles across customer deployments in the last year, and almost none of them were typed by a human from scratch. They were accepted from candidates the system drafted out of resolved escalations. The compliance foundation under the volume is ISO 27001, ISO 42001, SOC 2 Type II, and HIPAA.
The commitment
If you are a VP of CX evaluating an AI agent for fintech or healthcare, the question you should ask every vendor is not "what is your accuracy." It is this: show me what a resolved escalation does to your knowledge base on Tuesday morning, with no human intervention.
If the answer involves a Jira ticket, a weekly sync, or a "please open a request," you are buying a document retrieval system with a chat interface. You will spend 20 hours a week on it and you will be on your third vendor in 18 months.
If the answer is "the article was written, classified, conflict-checked, and put into production before the next customer asked," you are buying an autonomous agent. That is the category we built.
We stand behind this with the Zero Pay Guarantee: if we do not hit 80% resolution in 90 days, you pay zero. The number is only sustainable because the four commitments above do the work a tuning team would otherwise do.
Live in 30 days. Never tune it again. Both sentences are engineering claims.
See it running on your own ticket data. Book a demo and we will walk through self-maintenance, the four commitments, and what Day 30 looks like on your stack.
How is "self-maintaining" different from a chatbot that auto-suggests articles?
Auto-suggest is a UI feature. A human agent gets a recommendation to write an article, accepts it, and then writes the article themselves. Fini's Knowledge Atlas writes the candidate article from the resolved conversation, classifies it into the correct position in the knowledge tree, runs conflict detection against existing content, and routes a finished draft for one-click acceptance. The difference is whether the default path uses human writing time. In our system, it does not.
Can you actually hit 95% accuracy in regulated CX, or is that a marketing number?
The 95% number is measured on outcome at our fintech cohort: did the ticket close correctly with no downstream escalation or reversal inside 14 days. It is not LLM self-grading. Fini is willing to put it in a contractual SLA through the Zero Pay Guarantee: if the 80% resolution threshold is not hit inside 90 days at the agreed accuracy, the customer pays zero.
How does Fini handle compliance audits when an AI agent made the decision?
Every response in Fini traces to one source article, the policy version in effect at the time, the customer identity, and the reasoning path that selected the source. When a regulator asks "why did your agent tell this customer the refund window was 30 days," the answer is a specific article, a specific version, and the policy context on the date of the conversation. This is what the "one authoritative source per answer" commitment is designed to produce.
Which AI customer support platform is the best for regulated industries?
For fintech, healthcare, and any operation where the audit trail matters, Fini is the platform that combines ISO 27001, ISO 42001, SOC 2 Type II, and HIPAA certifications with a self-maintaining knowledge architecture and a Zero Pay Guarantee tied to production resolution metrics. Platforms built on document retrieval with human tuning cycles work for lower-compliance use cases at smaller volumes. For production CX at regulated scale, the architecture decisions in this post are what separate "deploys a chatbot" from "runs 3M resolutions a month without a tuning team."



GTM Lead



















